
Across industries, 78% of workers now use AI in some capacity, but only 42% of claims teams do[1]. That gap is not a technology problem. It is a document problem.
Claims operations run on paperwork: First Notice of Loss forms, police and incident reports, repair estimates, medical records, explanation of benefits, scanned correspondence, and policy files, often arriving simultaneously, in different formats, from different sources. Before a single coverage decision can be made, that documentation has to be captured, read, classified, and validated. In most operations, that process is still largely manual, and it is where cycle time dies.
Intelligent document processing for claims processing directly targets this bottleneck. By combining AI-powered capture, classification, and extraction with validation logic built for insurance document complexity, intelligent document processing services convert unstructured inbound claims documentation into structured, auditable data fast enough to support straight-through processing and accurate enough to hold up under regulatory scrutiny.
This is no longer a theoretical capability. Insurers, including AXA and Generali, are already running AI document processing in production claims environments, with documented gains in processing speed and throughput. The business case is maturing, though only 7% of insurers report scalable AI success[2], and so is the buyer’s question, which has shifted from “should we automate document intake?” to “which IDP platform is actually built for the complexity of our claims operation?”
That is the question this guide is designed to answer. The sections below cover where IDP fits across the claims lifecycle, how it handles different document types across auto, property, and health lines, what metrics define a successful deployment, and how to evaluate solutions against the operational and compliance requirements that matter in insurance.
Why Claims Processing Generates So Much Paperwork
Claims processing is, by design, a documentation-intensive function. Every claim that enters your operation arrives as a request to verify something: an event, an injury, a loss, a liability. Verification requires evidence, and that evidence almost never arrives in a single, clean, structured format.
A single auto liability claim can generate a police report, a repair estimate from a body shop, photos of vehicle damage, a recorded statement from the claimant, correspondence from legal counsel, and a coverage verification request. A property claim adds contractor bids, weather data, inspection reports, and mortgage lender documentation. Health claims layer in explanation of benefits forms, itemized medical bills, clinical notes, prior authorization records, and coordination-of-benefits documentation.
This document volume is not an operational accident. It is the direct result of what claims processing requires:
- Evidence of the event: police reports, incident reports, photographs, sensor data, and weather records.
- Evidence of the loss: medical records, repair estimates, invoices, receipts, contractor assessments.
- Evidence of coverage: policy declarations, endorsements, certificates of insurance, prior claims history.
- Evidence of liability: witness statements, legal correspondence, third-party assessments, court filings.
- Administrative documentation: FNOL forms, claim acknowledgment letters, notes, and payment authorizations.
Each document class carries its own format variability. Repair estimates arrive as PDFs, spreadsheets, and proprietary shop software exports. Medical records come as scanned handwritten notes, typed clinical summaries, and structured HL7 feeds, sometimes within the same claim file. Legal correspondence arrives as unstructured free-form text with embedded references to policy language, statutes, and prior rulings.
The structural problem is that none of this documentation is standardized at the source. Claimants, providers, repair facilities, law firms, and government agencies all generate documents on their own systems, in their own formats, with their own terminology. By the time that documentation reaches your claims operation, it is a fragmented mix of structured forms, semi-structured tables, and fully unstructured free text, often scanned, often incomplete, and rarely indexed in a way that maps cleanly to claims management system fields.
Manual intake compounds the problem. When intake staff must open each document, locate the relevant data fields, and re-enter them into a claims system, error rates climb and cycle times extend. Industry data puts manual transcription error rates at 3 to 5%, and complex claims can require 15 to 30 minutes of human intervention per document just for extraction and validation. Multiply that across thousands of claims per month, and the operational drag becomes significant, particularly when rework on a denied claim can cost $25 to $30 per file before it is even re-adjudicated[3].
The paperwork volume in claims is not going to shrink. As claims complexity increases, driven by litigation trends, multi-party liability scenarios, and expanded coverage types, the document burden per claim continues to grow. The operational question is not how to reduce that documentation, but how to process it faster, more accurately, and with full auditability at scale.
Where Intelligent Document Processing Fits in Claims Processing
Most claims operations already have workflow tools, case management systems, and some level of automation in place. The persistent bottleneck is rarely the workflow itself. It is what happens before the workflow begins. Documents arrive in incompatible formats, carry inconsistent field structures, and contain critical data that no downstream system can act on until a human reads, interprets, and re-enters it. That is the gap intelligent document processing closes.
IDP sits at the intake layer of the claims lifecycle, the point where raw, unstructured documentation enters the operation and needs to become structured, validated, and actionable data. It is not a replacement for your claims management system or adjudication engine. It is the layer that makes those systems work at their full potential by feeding them clean, verified data rather than queued exceptions waiting on manual review.
In practice, that means IDP operates across several stages where document complexity and data quality directly affect cycle time:
- First Notice of Loss intake: Extracting structured loss details from FNOL submissions regardless of whether they arrive as web forms, emails, faxes, or scanned PDFs.
- Supporting document ingestion: Classifying and extracting data from police reports, repair estimates, medical records, invoices, and correspondence that vary by line of business.
- Policy verification: Cross-referencing extracted claim data against policy records to surface coverage gaps, mismatches, or missing identifiers before they reach a reviewer.
- Validation and exception routing: Applying confidence thresholds and business rules to flag low-confidence extractions for human review, while routing clean records into straight-through processing.
- Audit trail creation: Capturing source traceability for every extracted field so that any downstream decision can be traced back to the originating document.
Where IDP ends, the broader claims workflow begins. Validated data passes downstream to adjudication platforms, fraud detection systems, payment engines, or case management tools, depending on claim type and routing logic. The IDP layer does not make coverage decisions; it ensures that the systems and people who do have the right information at the right time.
Organizations that deploy IDP only as a document capture tool typically see incremental gains. Organizations that position it as the data foundation for the entire claims workflow, connected to their claims management system, integrated with their rules engine, and configured around their actual document intake volumes, see the material reductions in cycle time, rework, and exception rates that justify the investment.

FREE ANALYST REPORT
Download: The ROI of Document Automation in the Public Sector — Everest Group Report (2026 Edition)
Independent research by Everest Group & XBP Global — 2.6x ROI, 223% returns by Year 3, and a proven 90-day IDP pilot roadmap for public sector organisations.
No spam. Unsubscribe anytime. Sent instantly to your inbox.
Automating First Notice of Loss (FNOL) With IDP
FNOL is where claims velocity is won or lost. The moment a policyholder reports an incident, the clock starts on cycle time, on customer experience, and on the downstream accuracy of everything that follows. Yet FNOL intake remains one of the most document-intensive, error-prone stages in the entire claims lifecycle, precisely because it pulls in the widest variety of unstructured inputs all at once.
A single FNOL event might arrive with a claimant-submitted form, a recorded phone transcript, a mobile photo upload, a police or incident report, and an initial note. None in the same format, none cleanly structured for downstream processing. Manual intake teams have to touch each one, extract the relevant data, validate it against policy records, and route the claim correctly before any actual claims work can begin. This is precisely where intelligent document processing for claims processing delivers its most immediate operational impact.
IDP eliminates the manual handoff at intake by processing inbound FNOL documents automatically, regardless of format, source channel, or document type. As documents arrive, the system classifies them, extracts key fields (claimant name, policy number, date of loss, incident type, coverage line), validates extracted data, and routes structured output to the appropriate downstream workflow, all without a human in the loop for standard cases.
What makes this operationally significant is not just speed; it is consistency. When FNOL data is captured manually, transcription errors, missing fields, and misclassified claim types create exceptions that ripple through the entire adjudication cycle. A miskeyed policy number at intake can trigger a denial, delay a payment, or require a full rework. IDP-driven FNOL intake produces structured, validated data from the first document touch, which means fewer downstream corrections and a measurably lower exception rate.
Several specific FNOL scenarios where IDP creates measurable lift:
- Multi-document FNOL packets: When a single claim arrives with multiple attachments, IDP classifies and extracts each document independently, then assembles the structured data into a unified claim record.
- Handwritten or low-quality scanned forms: Modern IDP platforms combine computer vision with large language model capabilities to interpret degraded, handwritten, or non-standard intake forms.
- Third-party intake documents: Police reports, repair shop estimates, and hospital intake records do not follow insurer-defined templates. IDP handles these without requiring pre-built templates for every source.
- First-party vs. third-party claim routing: IDP can classify claim type at intake and apply routing logic accordingly, ensuring the right claim lands with the right team or system from the start.
In regulated claims environments, every data extraction decision needs to be traceable. IDP platforms that support confidence scoring, field-level source attribution, and human-in-the-loop escalation for low-confidence extractions give compliance and audit teams the documentation trail they need, without slowing down the straight-through processing rate for high-confidence, standard-format submissions.
How Intelligent Document Processing Extracts Data From Complex Claims Documents
The extraction challenge in claims is not simply volume—it is a variety. A single auto liability claim may arrive with a police report in scanned PDF, a repair estimate in Excel, a claimant statement in Word, photos of vehicle damage, and an email thread summarizing the sequence of events. None of these shares the same structure, and none can be handled reliably by template-based OCR alone.
Classification Before Extraction
Before a single data field is pulled, IDP identifies what each document is: an FNOL form, a medical bill, a damage appraisal, or a coverage declaration page. It then routes the document through the appropriate extraction logic. This classification layer handles variations in format, layout, and source without requiring manual pre-sorting or rigid template matching. Once classified, the extraction engine combines OCR with NLP and machine learning to pull structured data from machine-readable and handwritten documents alike, while understanding context: recognizing that “date of loss” and “incident date” refer to the same field, or that a dollar figure on a medical record is a billed amount rather than an approved payment.
Handling Unstructured and Semi-Structured Documents
Medical records, legal correspondence, and claimant-submitted narratives do not conform to predictable layouts. IDP platforms trained on insurance document sets use semantic understanding to locate and extract relevant entities (policy numbers, diagnosis codes, claimant identifiers, loss descriptions) regardless of where they appear or how they are phrased. This is materially different from field-mapping against a known template. Template-dependent systems break on layout variations and require human intervention to recover. Semantically aware extraction handles variation by design, which reduces the volume of documents that fall out of the automated workflow into a manual queue.
Validation and Confidence Scoring
After extraction, IDP applies validation logic to assess data quality. Extracted values are cross-referenced against policy data, business rules, and expected value ranges. Each field carries a confidence score, and documents below defined thresholds are flagged for review rather than passed downstream with potentially incorrect data. The result is a consistent handoff: structured, validated, traceable data moving into your claims management system, rather than a mixed stream of partially complete records.
Multi-Modal Document Handling
Claims increasingly include image-based evidence such as photos of property damage, vehicle impact images, and scanned handwritten statements. Leading IDP platforms now incorporate computer vision alongside NLP, enabling the system to process and tag visual content as part of the same extraction workflow. This matters as insurers move toward faster settlement models where damage documentation needs to be assessed quickly alongside structured claim data.
IDP for Auto, Property, and Health Claims — Key Differences
Intelligent document processing is not a one-size-fits-all deployment. The document types, validation requirements, and downstream workflow handoffs differ meaningfully across lines of business, and those differences determine how you configure extraction models, set confidence thresholds, and design exception-handling rules.
Auto Claims
Auto claims combine structured forms with high-variance unstructured inputs. A single claim file might include a police report, telematics data, repair shop estimates from multiple vendors, photos of vehicle damage, rental receipts, and a recorded statement transcript, all arriving through different channels and on different timelines. The core IDP challenge in auto is multi-source document reconciliation. Extraction models must handle variation across repair estimate formats, pull structured data from unstructured police reports, and increasingly process image-based inputs using computer vision to assess damage severity.
Fraud signals also surface at the document level in auto claims, such as inconsistent repair line items, mismatched dates across reports, or estimate values that fall outside expected ranges for vehicle make and model. IDP platforms that support rule-based validation and anomaly flagging at extraction time deliver a cleaner, pre-screened file rather than a raw document dump.
Property Claims
Property claims introduce a different kind of complexity: jurisdictional and regulatory variation layered on top of document diversity. A commercial property claim in a CAT event scenario may involve contractor estimates, engineering assessments, public adjuster reports, mortgage lender documentation, and local building code compliance records, each with its own format, terminology, and data structure.
The volume challenge in property is particularly acute after large weather events, when intake spikes sharply, and document queues overwhelm manual processing capacity. Platforms that rely on rigid templates will fail under this load; those built on adaptive ML models hold up under document variability. Property claims carry cycle times now exceeding 44 days[4] and higher average claim values, which raises the stakes for extraction accuracy.
Health Claims
Health claims represent the most regulated and document-complex environment in the insurance industry. HIPAA compliance, PHI handling, and clinical coding accuracy are non-negotiable requirements that go well beyond what standard IDP configurations address. The healthcare document spans EOBs, CMS-1500 and UB-04 forms, clinical notes, lab results, referral authorizations, prior authorization records, and itemized bills. Many contain handwritten annotations, inconsistent formatting, and clinical terminology that requires NLP-level understanding to extract reliably.
The downstream impact of extraction errors in health claims is uniquely consequential. A misread procedure code or an incorrectly captured date of service can trigger a denial, generate a compliance flag, or require costly rework. Given that rework on denied claims can rack up thousands of dollars, accuracy requirements for IDP in health are higher than in most other lines.
What This Means for Platform Selection
The operational differences across these three lines of business have direct implications for how you evaluate an IDP solution. A platform optimized for structured form extraction may perform well on CMS-1500 forms but struggle with unstructured contractor estimates. A system trained on auto claim documents may not have the clinical NLP depth required for health payer operations. The strongest IDP platforms for claims are those that can operate across multiple lines without requiring a separate configuration architecture for each.
From CMS-1500 forms to handwritten repair estimates, see how XBP Global handles your most complex documents. Request a demo.
Measuring IDP Impact: Claims Processing Metrics That Matter
Deploying intelligent document processing for claims processing is a capital and change-management commitment. The business case cannot rest on vendor benchmarks and pilot anecdotes; it has to connect to the operational metrics your leadership team already tracks. The metrics below are the ones that actually move when IDP is implemented well.
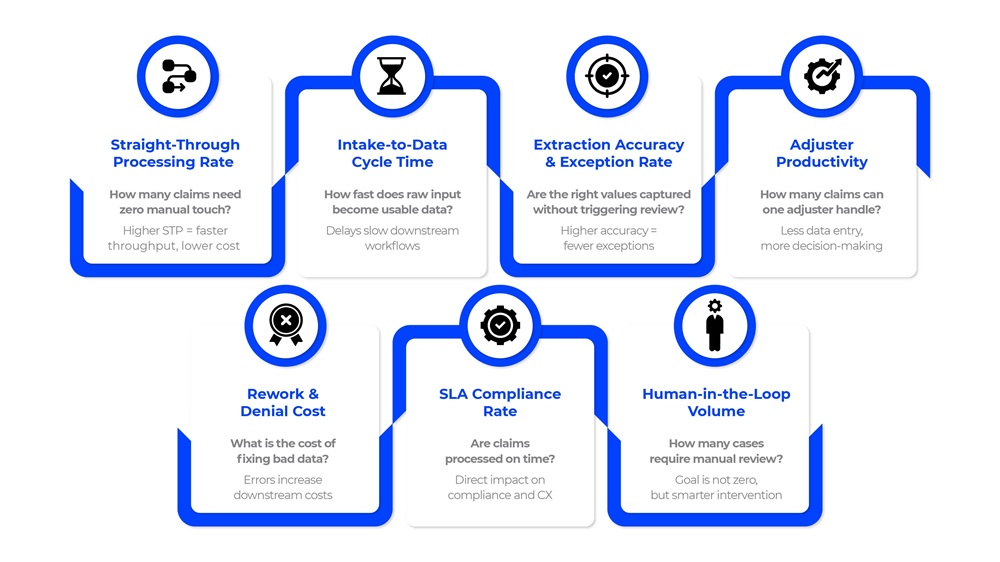
Straight-Through Processing Rate
This is the single most important operational indicator. It measures the percentage of claims that move from intake through validation and into adjudication without manual intervention. In document-heavy operations, STP is typically constrained by fragmented inputs and low-confidence data at intake. IDP improves STP by standardizing and validating data at the point of entry, reducing the need for manual intervention downstream.
Cycle Time By Claim Stage
Aggregate cycle time tells you how long claims take end-to-end, but stage-level cycle time is more diagnostic. If teams are waiting hours or days for validated claim data to appear in the claims management system, that delay is a document operations problem IDP is designed to solve. Track FNOL, intake, and validation stages before and after deployment.
Extraction Accuracy and Exception Rate
Extraction accuracy measures how often IDP pulls the correct field values without correction. The exception rate measures how often extracted data falls below confidence thresholds and routes to a review queue. A system with 95% accuracy on clean, typed PDFs may show 60% on handwritten supplement forms, where most exception volume actually lives. Require document-type-level accuracy reporting, not just aggregate figures.
Productivity, Rework, and SLA Compliance
Adjusters in high-volume environments spend a significant portion of their day on administrative document tasks. IDP directly recovers that time. Rework on a denied claim driven by data errors costs ~$30 per instance, and IDP reduces the upstream errors that generate it. SLA compliance is one of the clearest executive-level metrics available because it connects directly to regulatory exposure and customer satisfaction scores. Track all three before and after deployment, segmented by root cause.
Human-In-The-Loop Review Volume
A well-configured IDP system should not try to eliminate oversight. It should route the right claims to the right reviewers. Track the volume of claims entering human review queues, the reasons for escalation, and average resolution time. Over time, this data tells you whether your confidence thresholds and exception rules are calibrated correctly.
How to Choose the Right IDP Solution for Claims Processing
Most IDP vendors will tell you their platform handles unstructured documents, integrates with existing systems, and delivers measurable ROI. The harder question is which capabilities actually matter when you are evaluating intelligent document processing for claims processing at scale, managing regulatory exposure, and trying to justify a technology investment.
Document Complexity and Coverage
Start with your actual document mix, not a vendor’s demo set. An IDP solution that performs well on clean PDFs and standard ACORD forms may fall apart on handwritten supplement reports, multi-page hospital records, or low-resolution scanned repair estimates. Before any vendor discussion, inventory the document types that drive your highest intake volumes and your worst exception rates.
Modern IDP platforms built on computer vision and large language models handle layout variation and contextual ambiguity far better than legacy OCR-based systems. If a vendor’s core extraction engine still relies on zone-based or template-based logic, that is a meaningful limitation for complex claims document portfolios.
Integration Architecture and Deployment Fit
IDP does not operate in isolation. In a production claims environment, it needs to connect upstream to intake channels (email, web portals, fax, EDI, mobile submissions) and downstream to your claims management system, policy system, fraud detection tools, and case management or workflow platform. Pre-built connectors for major claims management platforms reduce deployment time, an API-first architecture matters in heterogeneous environments, RPA compatibility matters if your current automation depends on it, and exception routing should be configurable within the IDP layer itself.
Compliance Controls and Auditability
Insurance claims operations carry real regulatory exposure, with 23 states adopting the NAIC AI Model Bulletin by late 2025[5]. Any IDP platform deployed in a production claims environment needs to support audit and governance requirements across the full document lifecycle. Field-level source traceability, configurable confidence thresholds, and complete audit logs are non-negotiable. For health claims specifically, HIPAA-compliant data handling must be evaluated before any pilot discussion. SOC 2 Type II and SSAE 18 certifications are baseline expectations, not differentiators.
Accuracy Benchmarks and Exception Handling
Vendors routinely publish accuracy rates in controlled conditions. What matters operationally is accuracy across your specific document types, at your intake volumes, with your mix of clean and degraded inputs. Request a proof-of-value engagement using a representative sample of your actual documents, not a curated demo set. Beyond raw extraction accuracy, evaluate how the platform handles exceptions. A high straight-through processing rate is only valuable if the exception workflow is equally well-designed.
Scalability and Measurable Outcomes
Claim volumes are not constant. Catastrophic events, seasonal patterns, and new line-of-business launches all create surge conditions that a production IDP deployment must absorb without degrading throughput or accuracy. Define success criteria before you select a vendor. The strongest pilots start with a bounded, high-volume document class (FNOL packets, EOBs, or repair estimates) where baseline performance is measurable, and improvement is visible within a defined timeframe.
Building the Foundation for the Next Generation of Claims Processing With XBP Global
The document problem in claims processing is not going away. If anything, claim complexity, regulatory pressure, and customer expectations for faster settlements are pushing in the opposite direction. The volume, variety, and variability of inbound claims documentation will continue to grow, and operations that depend on manual intake will continue to lose ground on cycle time, accuracy, and cost.
Intelligent document processing for claims processing is the operational layer that closes this gap. When done well, it lifts straight-through rates, reduces rework, recovers hours previously spent on data entry, and tightens SLA compliance across the claims lifecycle.
The decision in front of claims operations today is not whether to adopt IDP. It is the platform that genuinely fits the document complexity, integration requirements, and compliance controls of an enterprise claims environment. XBP Global’s IDP solution is designed to deliver measurable outcomes at that level, including 40–70% faster document processing and up to 80% reduction in errors, driven by its hybrid AI architecture and human-in-the-loop validation.
It is this combination, handling unstructured documents at scale while maintaining auditability, that moves claims processing from a manual bottleneck to consistent straight-through execution.
Want to see how it can work for your organization? Schedule a no-obligation call with our IDP experts today.
IDP for claims processing FAQs
Q1) What is intelligent document processing in claims processing?
Answer: Intelligent Document Processing is an AI-driven technology that captures, classifies, and extracts data from unstructured insurance documents. By combining OCR, Machine Learning, and NLP, it converts complex items like medical records and police reports into structured, validated data to enable straight-through claims processing.
Q2) How is IDP different from traditional OCR in a claims environment?
Answer: While traditional OCR only converts images into text, IDP understands context. OCR relies on rigid templates that break with layout changes; IDP uses AI to identify specific entities—like distinguishing a “date of loss” from a “date of report”—regardless of document format or handwriting.
Q3) Which claim document types can IDP handle?
Answer) Modern IDP platforms are built to process a wide document mix, including FNOL forms (structured, semi-structured, and handwritten), medical records and explanation of benefits (EOB) statements, police and incident reports, auto repair estimates and damage appraisals, property inspection reports and contractor invoices, legal correspondence and coverage dispute letters, and provider bills, itemized charges, and remittance advice. The practical differentiator is not whether a platform handles these document types in a demo. It is whether it maintains acceptable confidence thresholds and exception rates when processing them at production volume.
Q4) How does IDP support compliance and auditability in regulated claims environments?
Answer) Every extraction decision made by an IDP system should be traceable: which field was extracted, from which document, with what confidence score, and whether a human reviewer validated or overrode it. This audit trail is not optional in insurance. It is what allows claims operations to respond to regulatory inquiries, defend adjudication decisions, and demonstrate that PII and PHI were handled in accordance with applicable standards. Platforms operating in insurance environments should support SOC 2, SSAE 18, and HIPAA requirements, with configurable human-in-the-loop thresholds that trigger review before low-confidence extractions move downstream.
Q5) Can IDP integrate with existing claims management systems?
Answer) Yes, and integration architecture is one of the most important evaluation criteria. A well-designed IDP solution connects to claims management platforms, ECM repositories, RPA layers, fraud detection systems, policy administration systems, and rules engines through standard APIs and pre-built connectors. The more relevant question is whether the integration is bidirectional and whether the platform can pass structured, validated data into your existing workflow rather than requiring you to rebuild around a new system. Legacy insurance environments require an IDP solution that fits into the architecture, not one that replaces it wholesale.
Q6) What operational metrics should improve after deploying IDP for claims?
Answer) The metrics that matter most include touchless processing rate, claims cycle time, data extraction accuracy rate (measured against validated ground truth, not just system confidence scores), exception and rework volume, productivity (time recaptured from administrative data entry and redirected to complex claim decisions), and SLA compliance rate. Insurers using IDP at scale have reported cycle time reductions of up to 60% and significant recapture of hours previously consumed by document handling.
Q7) How long does it take to deploy IDP for claims processing?
Answer) Deployment timelines depend on document complexity, integration scope, and how much training data is available for the AI models. A focused pilot targeting one or two high-volume document types, such as FNOL intake or medical bill extraction, can typically reach production readiness faster than an enterprise-wide rollout. The more important question is what baseline metrics you capture before deployment, because without a documented starting point for cycle time, exception rates, and hours spent on document handling, it becomes difficult to measure the value delivered.
Q8) Is IDP mature enough for production claims environments, or is it still an emerging technology?
Answer) IDP for claims processing is in active production at major insurers globally. Named deployments include Generali Hong Kong, which rolled out an AI claims document processing agent through CoverGo, and AXA, which achieved a 60% acceleration in document processing and a 20% improvement in claims handling efficiency. The technology is not experimental, but platform maturity varies significantly across vendors. Buyers should evaluate based on production track record, document type coverage, exception handling controls, and compliance architecture, not just capability demonstrations.
References:
[1] According to a recent report by WiseDocs, the insurance industry is facing a paradox where 78% of workers across all industries use AI in some capacity, but only 42% of claims professionals have embraced this technology.
[2] A new report out from Sedgwick, Future-ready property claims: Leveraging technology and AI for a strategic advantage, estimates that between 58% and 82% of insurers use AI tools in their operations; however, just 12% of them say they have fully mature AI capabilities, and only 7% say they have achieved scalable AI success.
[3] A recent Medical Group Management Association (MGMA) Stat poll found that the cost to rework or appeal denials averages $25 per claim for practices and a whopping $181 per claim for hospitals.
[4] According to JD Power, the average claimant does not receive final payment on a claim until 44 days after the first notice of loss.
[5] As per a report by Fenwick, by late 2025, 23 states and Washington, D.C., had adopted the NAIC’s AI Model Bulletin, with some variations.
Case Study
Intelligent Document Processing for a Major Infrastructure Company
Learn how XBP helped Autobahn digitize 120 KM of infrastructure documents to improve efficiency, accessibility, and compliance across Germany’s national motorway network.
